
The Challenge of Content Discovery in Modern CMS
Are your users struggling to find the right information within your vast Ibexa content repositories? In today's digital landscape, organizations manage immense amounts of content within their Content Management Systems (CMS). While powerful for content creation and organization, these systems often integrate traditional keyword-based search, which frequently falls short. It struggles to understand the true intent behind natural language queries, can't easily connect disparate pieces of information, and often presents users with a flood of irrelevant results. This leads to frustration, inefficiency, and missed opportunities for leveraging your valuable content.
At Netgen, we believe your content should work harder for you. That's why we've developed Ibexa RAG – a conversational AI assistant designed to leverage the potential of your Ibexa CMS content fully. Ibexa RAG provides accurate, context-aware, and, crucially, permission-aware responses, transforming how users interact with your digital assets. This solution not only enhances user experience but also demonstrates the advanced capabilities possible with AI integration into CMS installations.
What is Ibexa RAG?
At its heart, Ibexa RAG is built upon the Retrieval-Augmented Generation (RAG) architectural pattern. In simple terms, RAG combines the strengths of two key AI components:
- Retrieval: When a user asks a question, the system first "retrieves" highly relevant information from an external knowledge base, in this case, an Ibexa CMS content store.
- Generation: This retrieved information is then fed to a Large Language Model (LLM), which uses it as context to generate a precise, factual, and natural-sounding answer.
Why is RAG approach superior for enterprise content? Unlike LLMs that rely solely on their pre-trained knowledge (which can be outdated or prone to hallucinations), RAG ensures that answers are always grounded in your specific, authoritative content. This makes it ideal for providing reliable information from your internal documentation, product catalogs, support articles, and more.
The Ibexa Advantage: Permission-Aware Content Retrieval
One of the most significant differentiators of Ibexa RAG is its unique ability to integrate seamlessly with Ibexa's robust access roles and policies system. Standard LLM chatbot services on the market typically rely on web scraping publicly available website content. This means they can only index data that is accessible to anonymous users. If your Ibexa CMS contains sensitive, internal, or personalized information visible only to logged-in users with specific roles and permissions, external solutions simply cannot access or utilize this critical data. This poses a significant security and utility challenge for enterprises.
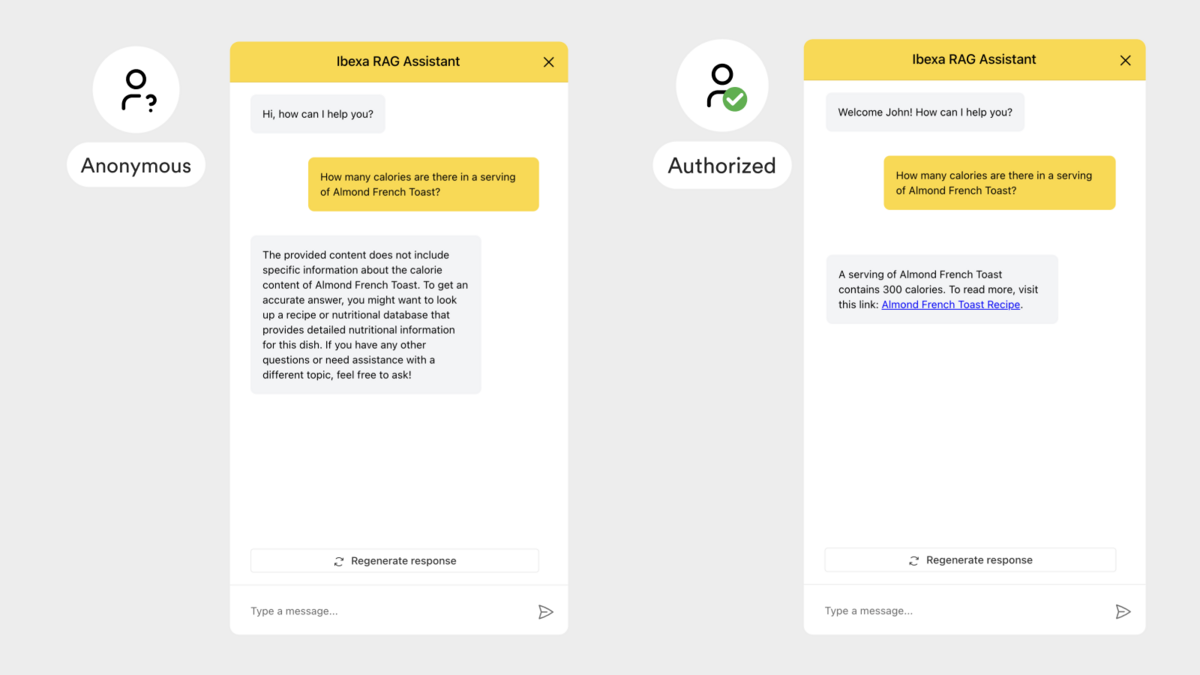
Only authorized user can access top-secret information on french toast recipe
Ibexa RAG solution is engineered for deep integration with the Ibexa DXP. Through our custom-built RAG bundle, it directly accesses and indexes CMS content while preserving associated metadata, including detailed permission-related criteria. When a logged-in user interacts with the chatbot, their specific roles and policies are securely passed to the system. Vector database (ChromaDB) then uses these permissions to filter the retrieved content, ensuring that the LLM only generates responses based on information the user is actually authorized to see. This creates a truly role-based, secure, and compliant chatbot experience.
Beyond Ibexa: Multi-Source Content Integration
While Ibexa CMS content is central, Ibexa RAG is designed for flexibility. It can integrate and draw information from multiple sources:
- Ibexa Content: Your primary, structured content store.
- Binary Documents: Uploaded internal documents (such as reports, or manuals) which are not part of Ibexa content.
- Web-Scraped Data: Information retrieved from external websites or sitemaps, handled using scraping tools like Firecrawl.
These diverse sources can be combined to create a comprehensive knowledge base, allowing the chatbot to answer questions that span across your entire digital ecosystem.
The Architecture: How Ibexa RAG Works
Ibexa RAG uses sophisticated foundations, but its underlying architecture is designed for clarity, efficiency, and scalability. Let's break down its core processes and components.
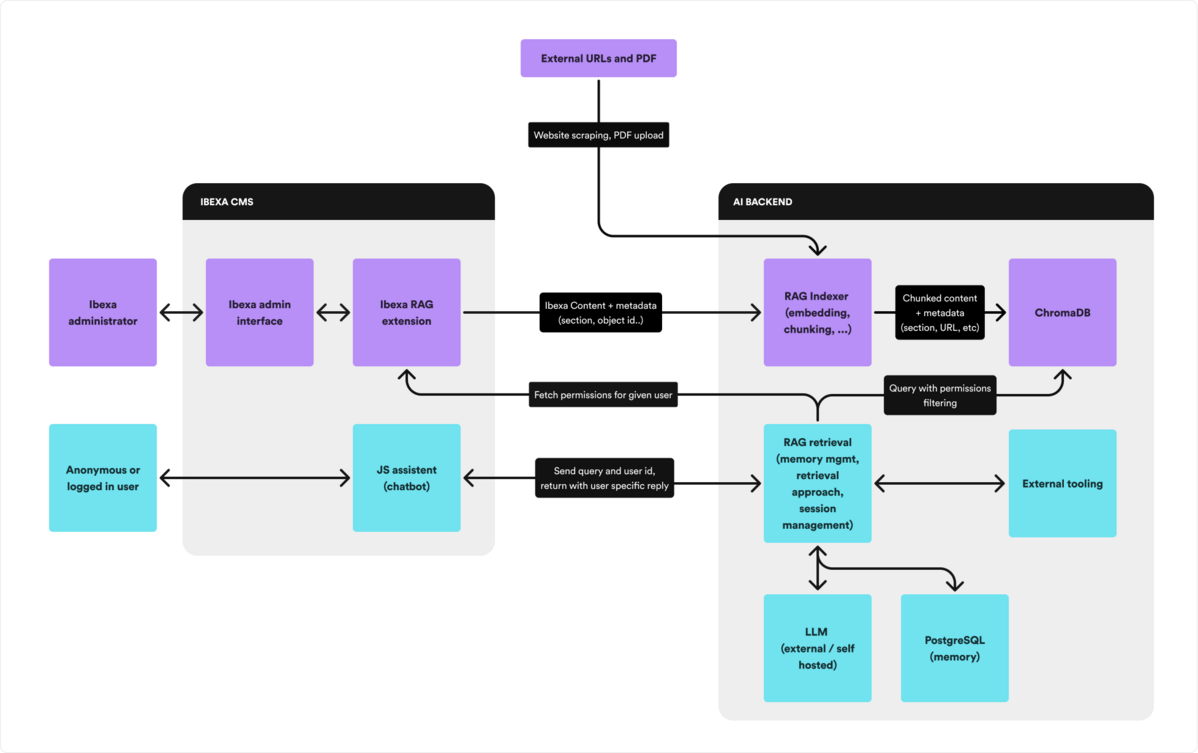
1. Content Indexing: Building the Knowledge Base
This is the foundational step where your raw CMS content is transformed into a searchable, AI-ready knowledge base.
- Ibexa Content Indexing: Our custom Symfony bundle is the workhorse here. It intelligently extracts and prepares all relevant content from your Ibexa CMS. A key aspect is the use of standard Twig templates for providing optimal output for each content type, utilizing information architecture specific to project use-case. Additional to templates that allow us to precisely define what and how content is extracted, necessary CMS metadata (like content and location identifiers, content section information, location of content in the content tree, etc) is extracted and stored in the vector database. This information is crucial for access control and permission filtering.
- Incremental & Asynchronous Indexing: Content in a CMS is dynamic. To ensure the chatbot always has the most up-to-date information, our system automatically tracks changes within the Ibexa CMS. Leveraging Symfony's Messenger component, content updates are processed in the background, pushing changes to the vector database incrementally. This means you don't need to perform full re-indexing constantly, saving time and resources.
-
Content Ingestion: Once content is extracted, the system processes it for ingestion. This involves:
- Chunking: Breaking down large documents into smaller, semantically meaningful "chunks" to fit LLM context windows and improve retrieval precision.
- Embedding Generation: Converting each text chunk into a numerical vector (embedding) using AI models, capturing its meaning.
- Metadata Handling: Attaching crucial metadata (most importantly, permission information) to each chunk.
- The Role of ChromaDB: Once processed, these chunks, their embeddings, and associated metadata are stored in ChromaDB, specialized vector database. ChromaDB is optimized for fast semantic search and is used for filtering results based on the rich metadata we provide, including user permissions.
2. Conversational Retrieval Flow
This is the dynamic process that unfolds every time a user interacts with the AI chatbot.
- User Query: The journey begins with a natural language question from the user, submitted via the chatbot interface embedded in user-facing web pages or administration interface.
- Security Node (LangGraph): This is the initial gatekeeper, powered by LangGraph. Every user query first passes through this node, which analyzes it for malicious intent, prompt injection attempts, or inappropriate content. If the query is deemed unsafe, a polite refusal is issued, preventing harmful interactions.
- Contextualization & Query Expansion: If the query is safe, the system leverages PostgreSQL-stored chat history to understand the user's intent within the broader conversation context. It can then expand the original query into multiple related questions, creating a more comprehensive search strategy for better retrieval.
- Permission-Aware Retrieval from ChromaDB: This is the core RAG step. The contextualized and expanded queries (now in vector form) are sent to ChromaDB. Here, the system performs a semantic search, but with a critical difference: it applies metadata filters based on the logged-in user's permissions. This ensures that only content the user is authorized to access is retrieved and considered for the answer.
- LLM Response Generation: The retrieved, relevant content (the "context") is then combined with the original user query and sent to a Large Language Model (LLM). The LLM is instructed to generate a precise, factual answer strictly adhering to the provided context, preventing hallucinations.
- Source Attribution & Memory Update: The generated answer is presented to the user, complete with clear links or references to the original sources from which the information was drawn. Simultaneously, the entire interaction (user message, AI response, and a summarized version for longer conversations) is stored in PostgreSQL to maintain context for future interactions, allowing for fluid and continuous dialogue.
Key Components & Technologies
Our solution is built on a robust tech stack that exemplifies the capabilities needed for advanced AI integration. Main components are:
Ibexa CMS and Ibexa RAG Bundle. The foundation for content management, our custom Symfony bundle integrated with Ibexa DXP handles efficient content preparation, extraction, and both full and incremental indexing.
Ibexa RAG Application
- LangGraph as the Brain: This powerful framework orchestrates the entire complex RAG process, managing the flow between security checks, conversation management, and tool adaptation. Its flexible, graph-based approach is crucial for building robust and adaptable AI systems.
- ChromaDB (Vector Database): Chosen for its efficiency in storing content embeddings and its crucial ability to filter results based on Ibexa permissions via metadata.
- PostgreSQL (Conversation Memory): Provides persistent storage for chat history, enabling seamless and context-aware conversations over time.
- FastAPI (API Layer): A high-performance Python web framework that serves as the robust communication backbone between the RAG application and user interfaces.
- Custom built Admin interface: Used as an administration panel for prompt management and vector store oversight.
- LLMs & Embedding Models: The system is designed for flexibility, supporting leading cloud LLMs (like OpenAI's GPTs or Google Gemini models) and offering the potential for integration with local LLMs (e.g., Llama variants) and various embedding models.
Security First
Security is paramount. The dedicated security nodes in the LangGraph application, combined with detailed permission filtering at the ChromaDB level, ensure that your data remains secure and interactions are safe and appropriate.
Key Features and Benefits
Ibexa RAG delivers tangible benefits for both your end-users and your business operations.
For End-Users
- Natural Language Interaction: Users can ask questions in plain language, just as they would to a human.
- Accurate, Contextual, and Permission-Aware Answers: Get precise information directly from your authorized content, tailored to the conversation's flow.
- Source Attribution for Transparency: Every answer comes with explicit references to the original documents, building trust and allowing for deeper exploration.
- Conversation Memory for Seamless Interactions: The chatbot remembers previous turns, making follow-up questions natural and efficient.
For Administrators
- Comprehensive Content Source Management: Easily manage and integrate content from Ibexa DXP, external binary documents, and web sources.
- Vector Database Control: Full oversight with capabilities for reindexing, resetting, and viewing indexed content.
- Prompt Template Editor: A powerful tool to fine-tune the system prompts and instructions, ensuring optimal response quality.
- Customizable Experience: Administrators can adjust settings like the LLM model, "temperature" (for creativity), and primary language.
Business Value
- Improved User Experience and Content Discoverability: Empower users to find information quickly and easily, boosting satisfaction.
- Reduced Support Queries: By enabling self-service information retrieval, you can significantly decrease the load on your support teams.
- Enhanced Data Security and Compliance: Strict adherence to Ibexa's permission system means sensitive information remains protected.
- Leveraging Existing Content Investments: Maximize the value of your extensive Ibexa content by making it more accessible and actionable.
- Future-Proofing with AI Capabilities: Position your organization at the forefront of digital innovation with a scalable and customizable AI solution.
Advantages Over Standard LLM Chatbot Services
When considering an AI chatbot for your enterprise, especially with an Ibexa CMS at its core, Ibexa RAG stands out significantly from generic LLM chatbot services on the market:
Native Adherence to Ibexa's Roles and Policies System
Standard LLM chatbot services typically rely on web scraping publicly available content. This means they can only index data accessible to anonymous users. Suppose your Ibexa CMS contains sensitive, internal, or personalized information that is only visible to logged-in users with specific roles and permissions. In that case, external solutions simply cannot access or utilize this critical data. This poses a significant security and utility challenge for enterprises.
On the other hand, Ibexa RAG is deeply integrated with the Ibexa CMS. Our approach allows direct access and indexing of content while preserving all associated metadata, including detailed permission criteria. When a logged-in user interacts with the chatbot, their specific roles and policies are passed to the system. The ChromaDB (vector database) then uses these permissions to filter the retrieved content, ensuring that the LLM only generates responses based on information the user is authorized to see. This creates a truly role-based chatbot experience, maintaining data security and compliance that generic solutions cannot provide.
Customization and Optimization:
Unlike external solutions that use generic web scraping, which often consumes data in a non-optimized way (missing context, struggling with complex content structures, including irrelevant info), Ibexa RAG leverages custom Twig templates, enabling highly efficient and precise content preparation for indexing, ensuring only the most relevant and clean data is fed into the vector database. This tailored approach dramatically improves the quality of your knowledge base.
The LangGraph-based architecture of Ibexa RAG allows for the introduction of enhanced retrievel logic by custom code and logic throughout the entire retrieval process. This level of control is simply not available with off-the-shelf solutions. We can:
- Implement sophisticated query expansion techniques to ensure comprehensive retrieval.
- Add custom tools for specific data lookups or integrations with other internal systems.
- Refine how conversation context is maintained, summarized, and utilized for more natural interactions.
- Introduce additional security checks or data transformations as needed.
This deep level of customization and optimization ensures that Ibexa RAG delivers highly accurate, relevant, and secure results, perfectly aligned with your unique business needs and data structures.
Beyond Ibexa RAG
Apart from Ibexa RAG, Netgen provides a set of services from the AI Engineering field:
- Custom AI chatbot cevelopment: Tailored AI assistants for your specific business needs.
- Integrating AI with your existing CMS: Seamlessly connect AI capabilities with Ibexa or other CMS platforms.
- Building custom RAG solutions: Develop bespoke RAG systems for your unique data sets and requirements.
- Creating LangGraph multi-agent systems: Designing and implementing AI systems with multiple collaborating agents.
- Consulting on AI strategy and implementation: Guide you through the complexities of AI adoption and deployment.
Conclusion
Ibexa RAG is more than just a chatbot; it's a powerful tool that changes how your users interact with your valuable content. By transforming your Ibexa CMS into an intelligent, conversational knowledge hub, you can enhance user experience, streamline operations, and unlock new levels of efficiency.
Ready to see Ibexa RAG in action or discuss how these capabilities can empower your next digital project? Contact us today for a demo or to explore the possibilities!