
We introduce some of the details on how we developed "Netgen Suggest" extension for eZPublish. Extension is shared with community: projects.ez.no/ngsuggest. Download and installation instructions can be found there.
In this blog post we introduce some of the details on how we developed "Netgen Suggest" extension for eZPublish. Extension is shared with community: projects.ez.no/ngsuggest. Download and installation instructions can be found there.
About the extension
"Netgen Suggest" is a eZPublish extension developed on top of eZFind that implements a drop down with suggestions on search fields, by using Solr facets. When a user starts typing suggestions are presented in drop down element underneath the search box. Suggestions are sorted by number of occurences in the search index. When a new word is added into the search box, suggestions are recalculated based on combination of all the words entered.
Extension is based on a jQuery component. For better results we created a new type of field for Solr. Existing 'ezf_df_text' field can be used but it concatenates the entered items, so often suggestions are not precise enough.
Implementation
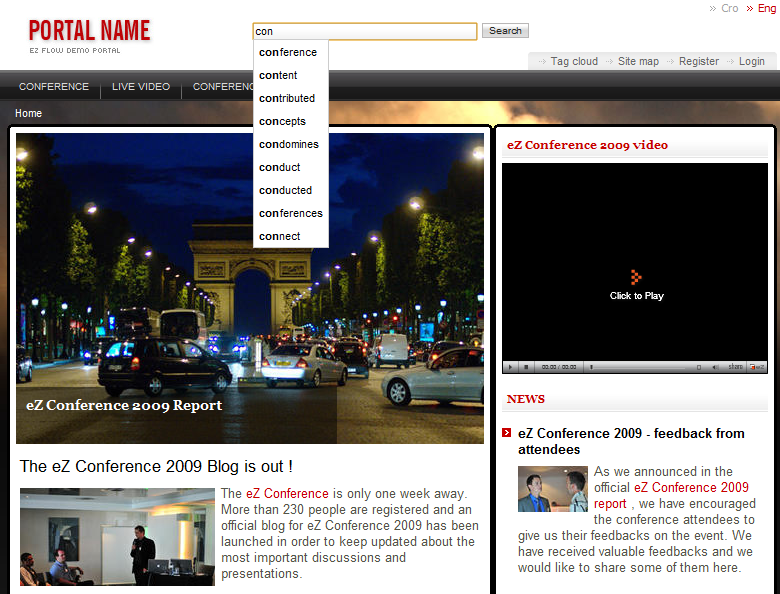
Netgen Suggest extension on top of ezwebin demo site
Creating Solr query
For retrieving search results from Solr we could use direct url but we wanted to control it better.
For this purpose we implemented a simple module as a configurable proxy. It constructs solr query using current installation_id and following settings, configured through ini settings:
- Limit: maximum number of facets
- RootNode: root node id as additional filter condition
- Classes: array of class ids as additional filter condition
- Section: array of section ids as additional filter condition
- FacetField: solr field from where facets are pulled
Solr query is constructed with following GET parameters:
- rows=0 (standard search results are not needed)
- facet=on (enable facets)
- facet.field=ngsuggest_text (facet field defined in ngsuggest.ini)
- facet.prefix=con (letters user entered)
- facet.limit=10 (maximal number of suggestions defined in ngsuggest.ini)
- facet.mincount=1 (minimum occurances for word to show up in suggestions)
- q=*:* (all index is searched)
- fq=meta_is_hidden_b:false+AND+meta_is_invisible_b:false (filter conditions: root node id, classes, installation id, .. )
- wt=json (return results in JSON format)
Output from Solr is simply redirected as output of the module. The module can be used from jQuery component as AJAX call:
/ngsuggest/searchsolr?id=[search_id]&keyword=[text]
where [search_id] is id of the search field (used for accessing relevant ini settings) and [text] are letters user entered.
If user enters 2 or more words query is the same except the 'q' parameter which is then used to narrow search with previous words.
Using jQuery component
To implement smooth visual representation we used a component developed by Tom Coote: jquery-json-suggestsearch-box and tweaked it to better fit our needs. The component catches every text change on input fields of class 'ngsuggestfield' and launches AJAX call to the module described above. Returned JSON data from the module is used to fill the drop down div element.
Solr results
For first tests we used 'ez_df_text' solr field because it contains all indexed strings. What quickly become apparent was that the results are flooded with concatenated words due to the 'ez_df_text' solr field type and how it works. Also, 'ez_df_text' field stores lot of meta content like node ids, installation ids, etc. which should not be exposed. To get better results new field type needs to be added to extension/ezfind/java/solr/conf/schema.xml under <types> node:
<fieldType name="text4suggest" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.StopFilterFactory"
ignoreCase="true"
words="stopwords.txt"
enablePositionIncrements="true" />
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1"
generateNumberParts="1"
catenateWords="0"
catenateNumbers="0"
catenateAll="0"
splitOnCaseChange="1" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
<analyzer type="query">
<tokenizer class="solr.WhitespaceTokenizerFactory" />
<filter class="solr.WordDelimiterFilterFactory"
generateWordParts="1"
generateNumberParts="1"
catenateWords="0"
catenateNumbers="0"
catenateAll="0"
splitOnCaseChange="1" />
<filter class="solr.LowerCaseFilterFactory" />
</analyzer>
</fieldType>New field type is defined as 'text4suggest' based on intrinsic type 'solr.TextField'. Following actions are applied when indexing happens (similar as when querying):
- text is tokenized by white space
- stop filter factory removes unwanted words defined in 'stopwords.txt'
- factory for slicing and combining words is called (useful for slicing words with numbers) but without concatenations
- lower case factory does casing normalization
Next, new field 'ngsuggest_text' is added under <fields> node:
<field name="ngsuggest_text"
type="text4suggest"
indexed="true"
stored="true"
multiValued="true"
termVectors="true" />Finally, new field should be filled with content under <schema> node:
<copyField source="attr_*" dest="ngsuggest_text" />
<copyField source="meta_name_s" dest="ngsuggest_text" />
<copyField source="meta_url_alias_s" dest="ngsuggest_text" />For demo purposes 'ngsuggest_text' is filled with content from all attribute fields and from 2 useful meta fields. This, of course, can be tweaked on project basis.